
码本坍塌:仅有少量的码本被使用。
paper认为原因是:早期确定性的SID分配,限制了对于码本的探索,从而导致不均衡和不稳定的优化。
1.Introduction
Tiger两阶段分离范式的缺点:第一阶段目标是表征准确,第二阶段目标是推荐更好。目标不匹配,会导致推荐性能下降;同时由于物品的全新表征SID一直保持预定义,不再改变,限制个性化和偏好感知的学习。
作者认为效果不好的主要问题:SID被预先计算出来,并且在二阶段保持冻结状态,二阶段不参与计算。
理想情况:二阶段的推荐任务,也可以用来反向优化codebook,语义ID就能适配下游的推荐任务。
问题:离散型导致的梯度断裂/梯度消失:
当连续的物品 Embedding 在 Codebook 中寻找最匹配的向量时,必然要经历一个 argmax 操作(或者最近邻搜索)。argmax 是一个阶跃函数(Step Function),它是不可导的(或者说除了跳跃点,梯度处处为 0)。这意味着,下游推荐任务计算出的误差梯度,在反向传播到 argmax 这一步时会瞬间归零,分词器根本接收不到任何更新信号。
-
使用STE来解决离散不可微的问题:
使用直通估计器件的做法:对于原先不可导的地方,直接让梯度直接原封不动的穿透过去,离散部分直接设置导数为1,连续部分用原来的导数。导致的问题:
直接导致了码本使用频率的极端两极分化。在训练早期,模型一旦偶然选中了某个码,这个码就会获得梯度更新,变得更加匹配输入特征;而那些没被选中的码则得不到更新。这就像马太效应一样,迅速催生出极少数被过度使用的高频码(主导了绝大多数的表示),而剩下的绝大部分码变成了永远不会被激活的低频码(或死码)。这就是所谓的“码利用率严重下降”。这种高频和低频码的极端分布,引发了两个连锁反应:
- 训练方差极大: 论文提到“STE 在各码本层级上的码均衡标准差显著更大”。因为每次 batch 训练时,模型都在几个高频码之间疯狂横跳,导致整个优化过程极其不稳定、高度波动。
- 性能受损: 因为大量的低频码被闲置,Codebook 失去了细腻表达物品特征的能力,所有的物品都被粗暴地塞进几个高频码的类别中。这种糟糕的表示直接拉低了最终的推荐质量(如 NDCG@10),让这种朴素的可微尝试宣告失败。
-
码均衡:体现出来不同codebook的利用率是否平均,我们希望越平均,效果越好,能表征的信息也越多。
码方差/训练方差:体现训练时的稳定性。
文章的贡献总结:
在本文中,我们提出 DIGER(Differentiable Semantic ID for GEnerative Recommendation),使语义ID能够与生成式推荐器进行联合学习。为实现稳定的联合训练,我们设计了带探索学习的可微SID框架(DRIL),并引入 Gumbel 噪声[19]以解决码本坍塌问题。受探索—利用(exploration–exploitation)范式[10]启发,我们进一步提出两种不确定性衰减策略,逐步降低注入噪声带来的随机性,以更好对齐训练目标。如图2所示,训练保持稳定,码使用均衡且性能稳步提升。注入的 Gumbel 噪声促进训练早期对码的探索,缓解坍塌并提升码本利用率。该设计使联合优化稳定可行,并持续提升下一SID生成。本文贡献如下:
• 我们提出 DIGER,一种有效的可微语义索引框架。据我们所知,这是首次有效实现语义ID与生成式推荐器直接联合优化的开创性工作。
• 为实现 DIGER,我们提出由两部分组成的范式:带探索学习的可微语义ID(DRIL),以及受探索—利用启发、配备两种不确定性衰减(UD)策略的框架。
• 在三个公开数据集上的实验验证了采用可微语义ID进行联合训练的有效性。
2.相关工作
- 联合优化:
BERT是典型例子,微调语言编码器,来让文本表示与用户-物品偏好对齐。
也进行了联合优化,但是由于文本表示也是连续的,所以整个梯度传导没有阻碍。 - 生成式推荐:
近期,ETEGRec[29]提出一种基于蒸馏的方法以对齐分词器与生成式推荐模型。但它并非通过可微语义ID实现联合优化,而是依赖交替蒸馏方案来处理语义ID的离散性:推荐器与语义ID分词器在不同阶段通过相互蒸馏知识进行训练。由于推荐损失无法直接通过离散索引过程反向传播,索引模块只能通过间接的替代目标进行优化。因此,由梯度流阻塞导致的核心不匹配仍未解决。
3.METHOD
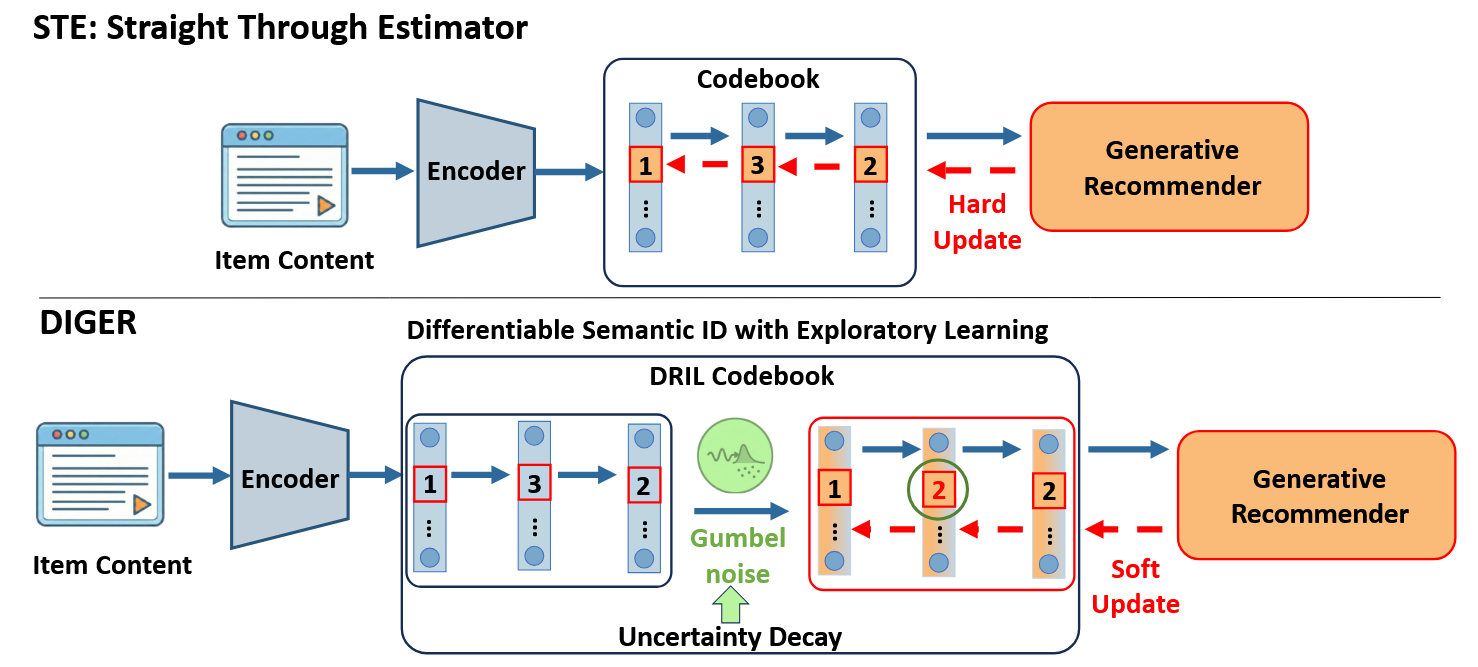
- 概述模型结构:
传统生成式推荐[35]通常采用两阶段训练范式。相比之下,我们表明联合优化在严格更大的可行解空间上运行,而两阶段设置中的目标不匹配即使在精确优化条件下也可能诱发任意大的次优性(附录A,备注1)。为通过直接梯度流实现有效联合优化,我们提出 DIGER(Differentiable Semantic ID for GEnerative Recommendation)。DIGER 通过受探索—利用范式启发的两部分学习方案进行训练:DRIL(DiffeRentiable Semantic ID with Exploratory Learning)通过基于 Gumbel 噪声的随机探索来学习离散语义ID并保持直接梯度流;不确定性衰减(Uncertainty Decay)逐步减少探索并引导模型稳定利用已学习SID。图3给出了整体框架。
3.1 DRIL differentable SID With Exploratory Learning
利用数学工具、gumbel-softmax将原本不可导的
离散查表过程,转换为既可以随机探索、又可以平滑计算梯度的过程
-
为什么硬指派会带来低熵?
-
硬指派:直接选择相似度最高的codebook。
-
硬指派带来的分布:所有的概率都集中在一个点上,是低熵状态。
作者证明了,如果能够提高这个指派过程的熵,就能有效促使模型使用更多的码 -
对于码均衡的说明:码均衡说明codebook使用频率基本平均,码不均衡也就是码本坍塌,部分codebook被广泛使用,部分被很少使用。
码均衡对于质量的影响:
码均衡相比于不均衡,最大化了码本的表达容量,可以让推荐系统能更好的区分物品之前的差别,也就是表达能力更好。 -
信息论视角的有关说明:
信息论中,各个码的使用频率趋近于均匀分布,信息熵会达到最大值,也代表携带的信息量最多,对物品的表征刻画也会更加饱满,后面的rec任务也会更加准确 -
硬指派导致低熵的原因:
训练刚开始时,物品的特征向量和 Codebook 里的向量都是随机初始化、瞎猜的。
硬指派会导致下面的连锁反应:
1.对于一个item,最开始可能碰巧找到最近的code1,所有梯度更新都给了这个code,其他code没有更新。其他code原地踏步
2.之后对于其他项目,会发现code1会比其他的更好,就会继续更新code1。
3.后果就是早期有几个item指派给code1之后,code1就得到很好的更新,但是其他code基本没有更新。- 独占更新: 进来一个 Item A,它通过
argmax在随机的 codebook 里碰巧找到了一个距离最近的 Code 1。因为是硬指派,所有的梯度都只传给了 Code 1,其他码完全接收不到梯度更新。 - 超级吸引子的诞生: Code 1 吸收了梯度后,参数被更新,它在特征空间里被拉得更靠近真实的物品数据分布。而其他的码还在原地踏步(保持随机状态)。
- 赢者通吃(过度自信): 当 Item B、Item C 进来时,它们会发现:被优化过的 Code 1 明显比其他那些没更新过的“原始废码”更顺眼、更相似。于是,
argmax再次毫不犹豫地把它们硬指派给了 Code 1。 - 码本坍塌: 就这样,Code 1(以及少数几个早期的幸运儿)垄断了几乎所有的匹配机会和梯度更新,变得越来越“万能”;而绝大多数的码因为一开始没被选上,就永远失去了被更新的机会,变成了死码。
这就是为什么论文指出:早期的确定性(硬指派)引发了“过度自信”,限制了对整个码本的探索,最终导致少数码主导(不均衡),码利用率严重下降。
- 独占更新: 进来一个 Item A,它通过
-
-
gumbel噪声的计算:
-
第一步:生成均匀分布的随机数。 从 到 的均匀分布中,随机采样一个数字 。
-
第二步:进行对数变换。 把这个均匀分布的 代入下面的公式,就能直接得到符合标准 Gumbel 分布的噪声 :
因为 是标准 Gumbel 分布的累积分布函数(CDF)。它的反函数正好就是 。通过这种数学变换,我们能用最廉价的均匀分布随机数,稳定地制造出符合 Gumbel 分布特性的噪声。
-
-
引入gumbel噪声的过程:
-
原先未引入gumble噪声时:计算item在第j层级的连续输出与codebook里面code的相似度logits:
公式描述:码本 其中表示第i个code。
-
现在每一侧层次选择匹配的code过程中,要引入噪声Gumbel:
是物品v在第j层级匹配到的code,是物品v在第j层级与的相似度,是物品v在第j层级计算时对于第i个code()引入的gumbel-噪声。。
-
-
上面的过程就是整个前向传播,但是针对
argmax,梯度仍然为0,所以作者提出了专门用于反向传播的软更新:-
gumbel-softmax分布:
其中 相互独立同分布, 为温度参数。
将这里的描述为软概率。 -
引入gumbel噪声,相对于之前硬指派,会明显鼓励更多的码本进行更新,会提升码本利用率。
-
软更新:
使用软更新,在反向传播的时候会对
RQVAE的codebook进行更新/物品embedding也更新。- 这里两者都更新,再加上后面真的实现了端到端,就类似于
码本:教其如何更好表示语义。
物品embedding的编码器:教他如何提取出物品关键特征,更好提取出来物品embedding。
- 这里两者都更新,再加上后面真的实现了端到端,就类似于
-

-
3.2 不确定性衰减策略
DIRL有很强的探索性,主要目的是为了防止码本坍塌,所以注入了噪声,让模型在训练的时候可以尝试不同的码。但是在推理阶段,为了保证稳定性和可复现性,还是会采用确定性的语义ID指派,(比如还是回到最开始的硬指派)。
由此产生一个问题如果在训练的后期,Gumbel 噪声依然很大,模型就会习惯于在有噪声的环境下工作。一旦到了推理阶段突然把噪声撤掉,模型就会“水土不服”,导致训练阶段和推理阶段实际使用的语义 ID 产生巨大差异,从而影响最终的推荐准确率。
- 方案:
设计一种“调度”策略:在训练早期保持噪声以鼓励探索,在训练后期逐渐把噪声关掉(降低不确定性),让模型慢慢习惯没有噪声的真实环境,使训练目标与推理目标对齐。
3.2.1 SDUD 基于标准差的不确定性衰减
-
引入一个参数(可训练的),用来控制SID指派的随机性,控制Gumbel噪声的标准差。
**有另外一层解释:噪声尺度,且必须**0。g本身是gumbel分布,标准差固定为1.28左右,乘以,标准差也要乘以,所以可以认为是在控制标准差。另外从公式角度,也能看到也在控制着随机性,大则随机性大。
反向传播的时候会使用:
-
效果:
较大的 对应更高不确定性并鼓励探索,而 产生近似确定性的指派,更贴近推理时选择。 -
设计新的损失函数,将原先的推荐目标损失 与 耦合如下:
其中是超参数,作用:它的作用有两点:一是防止分母为 0 导致程序崩溃;二是作为一个“刹车线”,决定噪声什么时候彻底归零。
观看第一部分,如果较大,也会倾向于大,也就会鼓励指派SID时的随机性。
而第二部分类似于正则化的作用,加了log,防止模型鼓励无止境的变大。 -
对上面的新的损失,对求导,再另结果为0,可以得到闭式解:
令
其中 与 相对于 视为常数。对 求导得到:
令 并将等式两侧乘以 ,得:
由于 的定义域要求 ,因此取正根:
最后,若进一步施加实用约束 ,则闭式解为:
闭式解:
这表明随着训练中 下降,最优噪声尺度 也相应收缩。此外,当 时, 趋近于0,从而得到近似确定性的SID指派并减少训练—测试不匹配。
-
公式18,背后就会代表我们想要的
理想动态过程:- 训练早期(探索期): 此时模型还很笨,推荐损失 非常大。由于 远大于常数 ,算出来的最优噪声 是一个比较大的正数。模型会自动维持较高的 Gumbel 噪声,继续在码本里大范围探索。
- 训练中后期(过渡期): 随着模型不断学习,推荐变得越来越准,损失 开始稳步下降。数学公式强制要求最优噪声 也必须跟着一起缩小。噪声开始衰减。
- 训练末期(利用期): 当模型收敛到一定程度,误差降到了设定的阈值附近(即 )时,括号里的计算结果会 。因为外面套了一个 ,此时 会被强制“锁死”在 。
最终结果: 噪声尺度 变成了 ,相当于 Gumbel 噪声被彻底关闭了。模型在训练末期的行为变得和推理时完全一样(近似确定性的 SID 指派),完美消除了训练和测试的不匹配问题。整个过程不需要人工干预,完全由模型当前的性能表现(Loss)自动驱动。
3.2.2 FrqUD 基于使用频率的不确定性衰减
策略:基于码本利用率进行推导。
核心思想:高频码表明过度复用,因此对他们施加Gumbel噪声来鼓励探索;低频码,采用标准确定性的指派。
-
在第e个epoch里面,我们认为码i的使用频率:(这里我们使用跨epoch的指数滑动平均EMA)
是第e个epoch里面第i个code,被使用的原始频率。是我们引入EMA之后的结果。 -
定义阈值来区分
高频码和低频码:
有
均匀的情况下,平均频率是
定义阈值:r是可以调整的比例,比如设置为1.5。使用频率大于的就是高频码,反之为低频。
-
对于高频,引入gumbel噪声,低频不引入:
-
混合logits:
如果你是高频码(热码): 必须加上 Gumbel 噪声来扰动你。如果你是低频码(冷码): 保持你原汁原味的真实相似度。
-
为什么是对于高频码添加噪声,而不是对于低频码;
我们现在的情况:当高频码添加了噪声并且降低的情况下,一些低频码由于本身就很优秀,这个时候可能赶超上来。
如果我们是高频码不动,对于低频码添加噪声:如果一个低频码由于添加了噪声超越了现在的高频码,很可能是因为这个噪声/概率/随机,而不是因为这个低频码本身的实力。
现在的方法,我们选到的低频码,也是可以保证它本身是有一定原来的实力,(实力的体现就是选择的概率大小),这种情况,模型选择一个概率大的低频码,能提升码均衡。
-
-
反向传播的时候用的软概率:
3.3 训练说明
RQVAE使用提前预先训练好的,此训练期间 与 始终处于更小的量级。结果是参数更新主要由 驱动,而其他项用于稳定优化。
和tiger相比主要差异在于:训练与推理流水线中省略了 RQ-VAE 解码器。由于我们的 RQ-VAE 目标是生成语义ID,我们直接在 RQ 量化后的表示上计算重建项,而不是将其解码回原始模态。
尽管本文研究码坍塌问题,我们有意未引入码多样性损失LETTER,以保持表述清晰并隔离仅由可微SID带来的影响。
因为论文的重点应该是端到端的可微的SID会带来怎样的影响,更倾向于单纯使用最终的推荐目标的损失来进行优化,而不添加种类多样性的正则化损失。
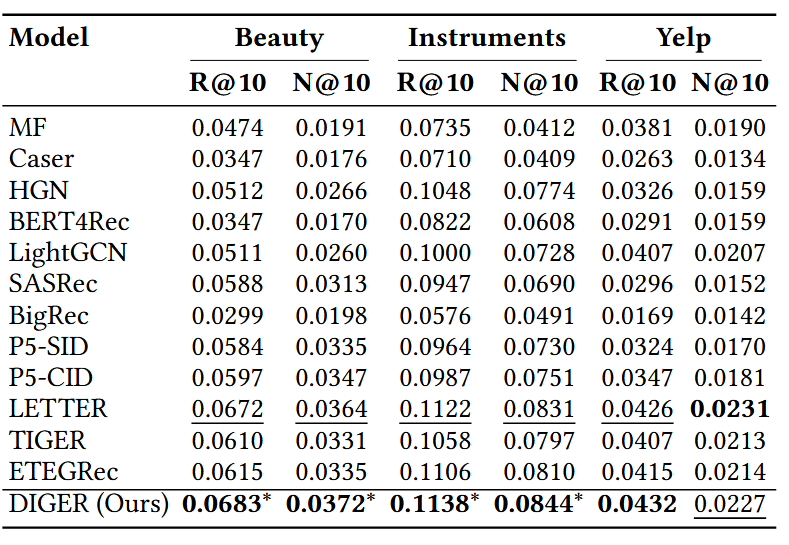
4.Experiment
5.总结
通过引入gumbel噪声和gumbel-softmax分布,将两个范式打通。
由于推理时不应该有噪声,所以指定不确定性衰减策略,让模型一步一步摆脱对于噪声的依赖。
相比与Etegrec的,仅仅加了两个对齐,Diger优化的损失就是推荐损失,并且真正端到端修改SID与相关参数。