
ETEGREC
1.Introduction
-
问题:
现有生成式推荐,SID生成与产生推荐结果两个阶段完全解耦,造成以下缺点:- item tokenizer感受不到推荐效果、也感受不到推荐要优化的目标。
- 后面的recommender看不到最开始item的上下文信息,只能看到物品最后SID。
后面的推荐相关训练不能用来重新优化前面学习到的SID,无法精炼item SID。
-
工作:
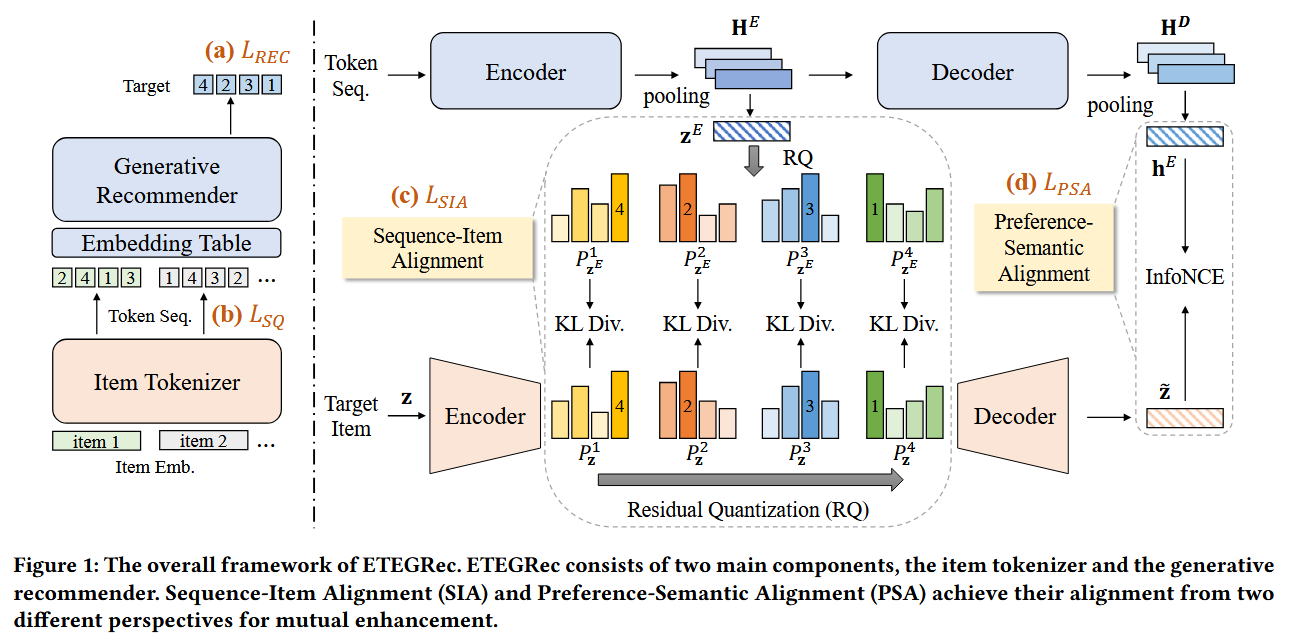
提出双编码器-解码器框架,可以将项目标记器和生成推荐器联合优化。
设计了面向推荐的两种校准方法:序列-项目校准、偏好-语义校准。目的:无缝整合标记器和推荐器,促进二者协同增强。
2.METHOD
2.1 形式化问题
项目标记化:把每一个item映射为多个tokens的过程
输入交互序列通过item tokenization之后得到标记序列:。
生成式推荐问题可以形式化为典型序列到序列学习问题:
2.2 双编码-解码架构
2.2.1 通过残差量化进行item 标记化来生成item token
-
对于项目i,使用其下文或协同语义嵌入(是item embedding维度),输入给标记器。最后每一个item被转换为语义ID,语义ID的组成是项目i在每一个层次量化后的token:
表示第l层,相应的token(被分配到的code)。 -
标记化具体过程:
首先:通过基于MLP的编码器将编码为潜在表示:每一个层级都有对应的码本:(为码本大小)。
其次:通过查找层级码本将潜在表示量化为序列化代码(称为标记),这个过程为:
为第层分配标记,为第层残差向量(设)。之后:可获得项目标记和量化表示。
将输入基于MLP的解码器重建项目语义嵌入: -
残差向量分配到对应code的过程:
表示残差被量化为标记的似然,通过与各码本向量间的欧式距离衡量:同时结合上述公式4。
-
损失函数:
确保重建语义嵌入紧密匹配原始嵌入;最小化码本向量与残差向量间距离。
2.2.2 生成推荐过程
采用类似于T5的Transformer编码器-解码器架构进行序列行为建模。
-
编码过程:
-
项目级用户交互序列和目标项目首先被tokenized为标记序列和。
-
对应标记嵌入(为推荐器隐藏大小)输入整个架构的第二部分-
生成推荐器进行用户偏好建模。 -
为什么维度是,X的长度为,每一个对应的code,都被转换为对应的维度的
code embedding,所以维度是。 -
标记序列encoding的过程:
其中为encode过程之后得到的
序列表示。
此时里面的每一个向量,已经整合好了序列的上下文信息。 -
**Transformer编码器的一个重要特征:输入和输出的形状保持一致。**都是维。
-
-
解码过程:
-
原本,构建新的解码器输入:。添加BOS是Transformer架构自回归必须的一步。
将与输入解码器提取用户偏好表示:其中为解码器隐藏状态,隐含用户对项目的偏好。
-
解码过程研究:
将一次性输入给解码器,对于第x个位置的预测,就不需要x-1位置的结果必须出来。我们将长度为 的 一次性输入了解码器,并且并行完成了计算。Transformer 保持输入输出长度一致的特性,直接“吐出”了包含 个向量的矩阵:
研究 矩阵的内部:
的第 0 行向量 :仅仅结合了历史 和 `[BOS]` 算出来的偏好。**(准备去预测 )** 的第 1 行向量 :结合了历史 、`[BOS]` 和正确的 算出来的偏好。**(准备去预测 )**…
的第 L 行向量 :结合了历史 和前面所有的正确 token 算出来的偏好。**(准备去预测结束符或后续行为)** -
训练时,可以一步直接得到结果。
推理时,每一步都必须等待之前结束再计算,一步一步来计算最后结果。 -
优势分析:(将一次性输入给解码器)
首先是迅速,因为可以并行处理每一个位置的结果。(因为掩码机制存在,这样并没有作弊问题)
其次是高效:对于每一个位置,都进行了训练。
如果我们真的使用前一步预测的结果来进行下一步的预测,第一步猜错时,后面就会一步错、步步错。训练效率很低。
这里的高效,可以表示为:Teacher Forcing(教师强制)避免误差累积。
-
-
推荐损失:
基于序列到序列范式优化目标标记的负对数似然:其中为目标标记第个标记,为前所有标记。通过此方式自回归生成目标项目标记。
2.3 面向推荐的校准
2.3.1序列-项目校准SIA
-
假设:
是协同语义嵌入。 是 `token级别的用户历史交互序列信息`对应的嵌入经过encode之后得到的结果。
一个物品的编码器隐藏状态与协同嵌入高度相关。 -
1.压缩序列信息
:Transformer 编码器的输出,它是一个矩阵(长度 × 维度),包含了序列中每个位置的信息。:取平均值,把整个序列的信息压缩成一个向量。
:一个简单的神经网络层,负责把推荐系统的“偏好空间”映射到分词器的“语义空间”。
结果: 就代表了从“用户历史”中提取出来的、对下一个商品的预测特征。 -
2.获取概率分布
根据公式6.
得到下面两个概率分布:
:把目标商品 丢进 RQ-VAE,在第 层码本(Codebook)上,它属于每一个 Token 的概率分布。
:把用户序列特征 丢进同一个 RQ-VAE,它认为下一时刻应该产生的 Token 概率分布。 -
3.强制分布一致:
KL 散度:是衡量两个概率分布有多不像的指标。值越大,分布差异越大。
对称性:同时计算 和 的散度,让对齐更稳健。
含义:这个损失函数要求,对于 RQ-VAE 的每一层( 到 层),从“用户历史”预测出来的 Token 分布,必须和“真实商品”生成的 Token 分布保持同步。
2.3.2 偏好-语义校准
-
参与校准的两部分:
要在连续的向量空间里做对齐,我们需要找到代表“用户”的向量和代表“商品”的向量:-
1.用户的宏观偏好
解码器输出矩阵 的第一列
Transformer 解码器在输入 符号后,输出的第一个隐藏状态向量。
为什么使用第一列:
此时,解码器还没开始预测任何具体的 Token,它完全凭借编码器传来的历史信息 酝酿出了对下一个商品的整体预期。所以,这个 包含了最纯粹的、未被具体 Token 细节干扰的“用户整体偏好”。这里的偏好是decoder在收到bos之后的输出,应该是矩阵里面第一行,paper里面一直用列,自己知道就好
-
2.目标商品的重建语义:
是RQVAE从物品提取出token之后,再试图通过解码器还原回去得到的向量。
-
-
校准假设:
用户心里的整体预期() 和 **这件商品的内在灵魂()**应该是有联系的。 -
对齐过程:(采用对比学习里经典的
infoNCE损失)-
:
分子 :
代表当前训练的这一个批次(Batch)里的所有其他用户(Batch Size 是256,就会有255个其他用户的偏好 )。分母把目标商品和**所有用户**(包括真用户和 255 个路人)的相似度加起来。
计算目标商品 和当前用户偏好 的余弦相似度。我们希望这个值越大越好。
分母:意义:
在当前批次的一堆用户中,目标商品 必须觉得当前的 是最匹配的,对其他人的偏好不理不睬。 -
损失里面的第二部分的解释与上面类似。
-
:
3.总结
过去Tiger的范式,都把id生成和推荐结果两个阶段解耦,作者认为这样不容易让两部分深度融合,希望可以根据后面的推荐结果的好坏来训练到第一阶段的模型,也就是实现端到端的统一框架。
作者设计两种对齐,序列-项目校准与偏好-语义校准。第一个对齐:1>用户交互历史token化之后再通过encoder得到的编码器隐藏状态 2>物品的协同嵌入。1代表序列、2代表项目。第二个对齐:3>第二阶段的解码器输入[BOS]之后得到的输出 4>物品的重建语义嵌入。3代表用户的偏好、4代表物品的语义。
通过上述两种对齐,设置对应损失函数,训练中,二阶段的推荐相关损失可以直接传播到(影响)一阶段的ID生成,两部分不再解耦,实现端到端。
- tiger和letter里面,id生成更像是一个预处理步骤,这里的etegrec就是把两部分联合起来,实现端到端的统一框架。