
1.Introduction
现有生成式推荐问题:
- 1.目标不一致:
物品的embedding结果学习的目标:更加稠密/丰富的表示物品。
SID的目标:有效的用于next-token预测中。
两个阶段,不是端到端训练,会导致产生次优的SID表示。 - 2.语义退化:
生成 ID 时只用了预训练的嵌入,丢失了原始物品的多模态特征(如图片、文本细节)。 - 3.误差累积:
分层量化时,每一层的误差会传递到下一层,导致深层的 ID 噪声很大。
自己理解一下三个问题:
- 目标不一致:
第一阶段训练出来的embedding,并不知道自己之后要被量化,所以不一定适合。 - 语义退化:
多模态信息转换为embedding,本身是一种有损压缩,有信息被舍弃,这个embedding用到后来,本身就自己扔掉了一些信息。 - 误差累积:
- 现有的 SID 生成通常使用 残差量化 (Residual Quantization, RQ)。
- 它的工作原理是:
- 第 1 层 ID 逼近原始向量 。
- 算出残差(剩余误差)。
- 第 2 层 ID 逼近残差 。
- 算出残差 。
- 第 3 层 ID 逼近残差 。
- 问题: 随着层数加深,残差 变得越来越小,包含的有效语义越来越少,主要成分可能是噪声。且每一层只能看到上一层的“残差”,看不到完整的原始信息。这导致深层的 SID 往往非常嘈杂,包含的语义信息很稀疏,可靠性极低。
2.METHOD
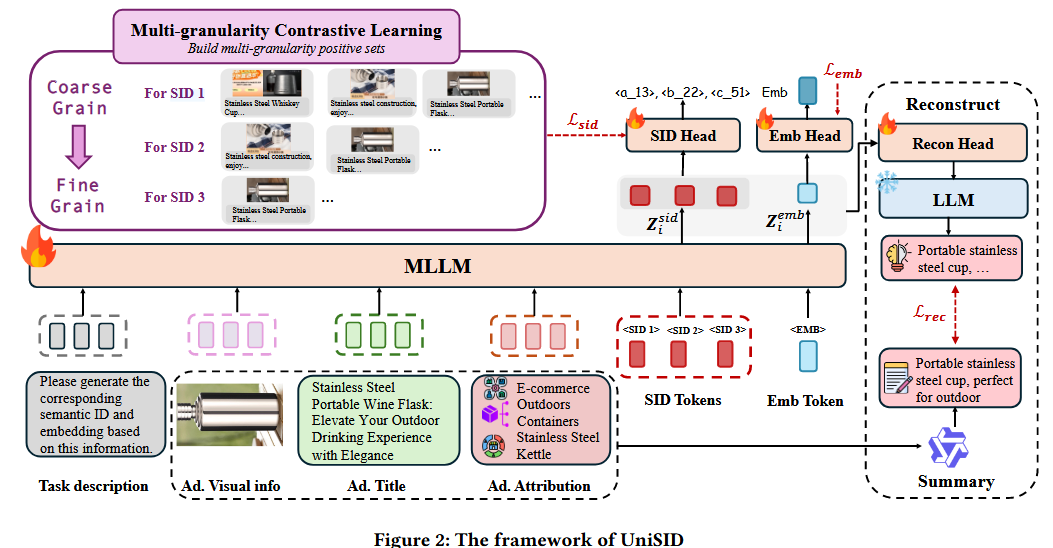
和之前类似SEQREC和TIGER有很大区别,论文是直接拿预训练好的大模型,在此基础上进行微调。
2.1增强广告的输入
由于模型主要面向场景是广告推荐,所以对输入数据做了工作。
在传统的推荐系统中,模型通常只看图片或标题。但在广告场景里,这远远不够。
举例:引入广告对应的属性,来促进模型对于广告的理解/目标用户群体的理解。
为了促进模型对于广告的理解,设计下面的输入:
- 广告指令提示:
输入最前面,写prompt内容为:“Given the following advertisement information, please generate the corresponding Semantic IDs and embedding.”告诉大模型这个是要生成SID和Embedding - 图像和文本:
提供丰富的上下文信息。 - 广告属性信息:
引入行业与多级类目信息以降低语义歧义。
比如水杯:层级类目路径为“日用百货 餐饮具 饮具 → 水杯”。 - SID词元和Embedding词元:
我们在广告输入之后引入多个可学习的SID词元。在下一词元预测过程中,这些词元通过共享MLLM聚合多模态与属性增强特征,所得表示随后由专门的SID head映射以生成离散SID。该设计免除了级联压缩的需求,为端到端SID生成建立了稳健基础。
借助下一词元预测机制,嵌入词元以此前SID序列为条件,从而融合原始广告内容与由粗到细的语义信息,获得较仅基于孤立原始数据更丰富的表示。
输入部分可以理解为拼接一个序列:
[系统指令] + [广告图片] + [广告文案] + [多级类目属性] + [SID Token 1] + [SID Token 2] + [SID Token 3] + [Embedding Token]
一长串直接喂给 MLLM,模型过一遍:
- 读到前面,理解了广告;
- 读到 SID Tokens 位置,吐出我们要的 ID 序列;
- 读到最后一个位置,吐出我们要的高质量向量。
这就是Unisid实现**“单一目标、联合优化、端到端生成”**的基础物理架构!
2.2 SID 和 Embedding的生成过程
-
第一步
输入信息给大模型,得到全局矩阵假设指令+图文+属性+占位符,一共拼成了500 个词元 (Tokens)的序列。
尺寸:`[500]`经过 MLLM 计算: Qwen 模型会对这 500 个词元进行极其复杂的注意力计算。
尺寸:`[500, 3072]`,3072是我们假设Qwen隐藏层模型维度。 -
第二步
提取SID词元与嵌入词元位置上的表示,分别记为 与 。500 个向量里前498个都不需要,
- 索引499的向量:
抽出来的 :尺寸是[3072]的一维向量。(它吸收了前面的图文信息,专门用来做分类)。 - 索引500的向量:
抽出来的 :尺寸是[3072]的一维向量。(它吸收了全部信息,用来做最终的连续语义)。
- 索引499的向量:
-
第三步
双头投影。
上面两个3072维度的向量都是LLM内部的"通用语言",需要通过Linear Layer映射为下游任务需要的"尺寸"。-
嵌入生成:
- 是一个权重矩阵,尺寸为 `[3072, 1024]`。
- 计算过程:
[3072]乘以[3072, 1024]的矩阵。 - 结果 : 尺寸变成了
[1024]。 - 结束Embedding的提取,这个 1024 维的向量就是你拿去给传统推荐系统(比如双塔模型)算相似度用的最终 Embedding。
-
SID生成:
假设:我们L=3,每层需要从K=2048类别里面选一个,实际就是包含3个多分类任务的预测。
需要输出 3 组概率分布,总共需要 个数字。- 所以, 的权重矩阵尺寸被设计为
[3072, 6144]。 - 计算过程:
[3072]乘以[3072, 6144]的矩阵。 - 结果 : 尺寸变成了
[6144]。一个超长的概率(logits)向量。
- 所以, 的权重矩阵尺寸被设计为
-
-
第四步
超长概率向量切块,划分类别。-
将长度为 6144 的向量 。我们直接把它平均切成 块:
- 第 1 块 (): 第 1 ~ 2048 个数字。(代表粗粒度第一层的 2048 个备选 ID 的概率)
- 第 2 块 (): 第 2049 ~ 4096 个数字。(代表中粒度第二层的 2048 个备选 ID 的概率)
- 第 3 块 (): 第 4097 ~ 6144 个数字。(代表细粒度第三层的 2048 个备选 ID 的概率)
-
对每一块及逆行argmax操作,找到2048数字里面最大的位置,从而划分到对应类别。
比如:在第一块的 2048 个数字里,假设第1024个位置的数字最大。那么第一层 ID: 。
这个过程进行三次。
-
2.3 多粒度对比学习训练
这里是论文自己提出的有关自己模型结构里面SID部分,优化的损失函数。
-
根据层次来设定正样本:多粒度对比学习策略
根据广告/物品相关性,在每个语义层次自适应确定正样本关系。
随着层级加深,查询样本与正样本的相似性要求更高,从而充分体现SID的层级特性。 -
在每一个层次都施加对比学习,每一层级都采取不同的正样本。
使得每一层次的SID可以吸收对应粗细粒度的语义,避免产生:细粒度SID吸收粗粒度噪声的情况。 -
对于每一个粒度层l,定义正样本集合,集合里面的物品在这个层次共享同一分类结果。
表示物品在粒度层的SID嵌入(2048维度的向量),与分别表示同层的正样本与候选样本的嵌入;
候选集:,包括这个粒度层次下面的正样本和负样本。
优化目标:第一个求和公式,就表明在计算损失时,会针对每一个层级来单独计算对应的损失。
-
对于Embedding的结果进行的训练:
正样本对与负样本集合。
上述损失会使得语义相近的emb更加相近,拉远语义不相近的样本。
2.4 基于摘要的广告重构
针对广告场景,做的另外一个模块的优化
-
原来的广告场景的困境:
原始广告数据即便包含多模态内容与结构化属性,也可能未显式暴露对准确广告理解至关重要的高层语义信息。 -
做法:
将广告相关信息输入给LLM,同时给要总结的prompt,比如“总结目标用户群体”,得到当前广告的
语义摘要。将广告摘要也作为输入的一部分,输入给上述的模型里,得到新的SID表示与物品嵌入。
将两个嵌入拼接,输入到一个简单线性投影层,得到隐状态。隐状态随后作为条件输入送入LLM,在下一词元预测范式下重构语义摘要。重构目标通过标准交叉熵损失优化:
其中表示摘要序列的第个词元。
通过仅依赖SID与嵌入重构高层语义摘要,该范式显式促使SID编码具有判别性且高层的语义信息(这些信息在原始广告数据中并不可直接获取),从而提升其在复杂广告场景中的有效性。
-
总结这里的做法:
为了让SID可以有更加高层的语义信息,首先通过LLM构造这样的信息给模型,再计算得到上面的两种嵌入表示(一个是SID相关一个是Emb相关),两种表示再进行拼接和经过线性层的操作,得到隐状态。
使用这个隐状态与经典的自回归模型里预测下一个词元的交叉熵损失,来进行训练,使得模型学习到的SID和Emb表示可以涵盖更加高层的语义信息。
2.5 联合优化
优化三个互补目标:(i)SID的多粒度对比损失,(ii)嵌入的对比损失,以及(iii)由基于摘要的广告重构机制产生的重构损失。
3.EXPERIMENT
- 数据集:
实验涉及到广告数据集和Beauty。
广告数据集具有丰富的多模态信号和论文里面专门需要的层级类目结构。 - 对比方法:
- 为评估SID生成有效性,我们采用基于残差量化的SOTA SID构建方法,包括RQ-VAE与RQ-KMeans。这些方法遵循“先嵌入后SID”的两阶段范式,并被广泛用于现有GR框架中。
- 为评估UniSID生成嵌入的质量,我们与先进的多模态嵌入方法对比,包括GME、LamRA与VLM2Vec2。这些方法聚焦于从多模态广告内容学习统一表示。
- 在Beauty数据集上纳入代表性推荐基线,覆盖判别式与生成式范式。具体包括经典DLRM方法Bert4Rec、LightGCN与SASRec,以及GR方法BIGRec、P5-SemID、TIGER与LETTER。该基线集合支持从多角度对UniSID进行公平且全面的评估。
4.SUMMARY
总结文章内容:
文章主要提出三个目前tiger范式的问题:1.无法端到端优化。2.原始多模态信息使用会遭到压缩。3.误差累积。首先说误差累积的问题,原因是RQVAE残差量化时会造成,文章采用完全不同的范式,不会有这个问题。(并没有针对这个问题做什么改进,而是选择新的范式,就没有这个问题了😅 )
然后来看模型结构,作者是直接利用LLM来得到想要的表示。首先是构建输入:首先是指令告诉LLM,要基于下面的信息生成SID和Emb,之后输入图像和文本信息(这里直接输入多模态信息,也有效缓解上面的第二个问题😇),以及SID和Emb占位符。这里和tiger很不一样,是直接用预先训练好的LLM来做提取,输入里面的占位符,就是在让LLM生成最后需要的SID表示和Emb表示。
得到SID表示和Emb表示之后,再经过两个各自的映射部分,得到真正的SID表示和嵌入表示。(具体过程看上面内容)优化上采用的是对比损失,对于SID和Emb的结果,联合进行优化,同时文章这里为了让SID学习到的是具有粒度的内容,会根据层次来不断进行优化。(由于这个范式和原先tiger范式区别很大,是在微调大模型,明显就是在做端到端优化🤔)
总结一些其他相关细节:
-
和tiger做性能对比的时候:
把TIGER第一部分生成ID的过程替换为现在的SID过程。
会对于Beauty数据集的训练集,每一个item构建对应的更多的输入信息/高层语义信息,用于训练。
自我认为,拿参数量如此大的模型和tiger一起,没有可比性,文章是在微调大模型。 -
在输入里面添加SID占位符和Emb占位符,就可以得到最后的SID结果和嵌入表示:
LLM本身是自回归生成的,会根据输入一步一步生成对应结果,当输入到这里的占位符对应token时,就会输出SID有关的结果和embeding。
这里的占位符是可训练的,最后两个位置会被训练为:[SID占位符]被训练成了专门问:“前面的各位,请告诉我如何把你们分类到离散的格子里?”[Emb占位符]被训练成了专门问:“前面的各位,请告诉我你们最细腻的连续语义特征是什么?”
这里是整个模型端到端的关键,也是区别于之前Tiger范式的区别。
-
微调了大模型的什么内容:
可以用一个**“大学生实习”**的例子来比喻:- 现成的 Qwen 模型 = 一个刚毕业的名牌大学生(底子好,通识能力强,但不懂业务)。
- 冻结 ViT = 他的视力(不用重新教他怎么看东西,这是天生的)。
- 微调 MLLM = 对他进行岗前培训。让他别整天写诗了,专门学习怎么看广告、怎么分类商品。他的**脑回路(权重)**被重塑了。
- 训练占位符 & 投影头 = 发给他一套专用的工具和表格(SID, Emb)。教他怎么填表,怎么把脑子里的想法写成公司要求的格式。