
LETTER
1.introduction
生成式推荐放到推荐领域的一个关键问题是,item tokenization,项目标记化。
item tokenization的过程就是,通过标识符索引每一个项目,目的是弥补推荐数据和LLMS语言空间之间的差距。
1.1现有item tokenization的方法
- 1.ID标识符
为每一个物品分配一个数字字符串。
优点:唯一。
缺点:没有出现过的物品,没有映射,无法知识迁移到没出现的物品上,冷启动难。
缺点:没有语义信息。 - 2.文本标识符。
做法:将item的文本信息作为标识符,比如title里面的几个单词。
优点:携带语义信息。
缺点:无协同信号。
缺点:粒度不匹配,token没有从粗到细的层次化分布。 - 3.基于codebook.
做法:vqvae,生成语义ID。
优点:层次化,有一定泛化能力。
缺点:无协同信号。
缺点:码分配不平衡。由于训练数据的偏差,某些码会被频繁使用(高频码),而另一些码很少出现。这使得模型在生成物品时倾向于生成那些由高频码构成的物品,造成推荐偏差(即热门物品更容易被推荐,冷门物品更难被生成)。
1.2 理想item tokenization特点
• 将层次化语义整合到标识符中,标记序列首先编码广泛和粗粒度的语义,逐渐过渡到更精细的细节。这与生成式推荐的自回归生成特性一致。
• 在标记分配中融入协同信号,确保用户行为中具有相似协同信号的项目拥有相似的标记序列作为标识符。
• 提高标记分配的多样性以减轻项目生成偏差,从而确保项目生成的公平性。
1.3贡献
LETTER-可学习item tokenization。
对于基于codebook生成标识符的方法,用三个正则化增强。
1.语义正则化首先整合残差量化VAE(RQ-VAE)[16]将项目语义信息转化为层次化标识符[32]。
2.协同正则化利用对比对齐损失将RQ-VAE中的语义量化嵌入与训练良好的CF模型(如LightGCN[11])的CF嵌入对齐。
3.LETTER引入多样性损失增强码嵌入多样性以减轻码分配偏差和项目生成偏差。
另外:提出排序引导生成损失从理论上增强生成模型的排序能力。
总结:LETTER通过同时考虑标识符中的层次化语义、协同信号和码分配多样性,能实现优越的项目标记化。
1.4 TIGER里对于协同信号的处理
在LLM训练阶段将协同信号注入标识符的标记嵌入中(如TIGER[32]和LC-Rec[50])。
TIGER第一阶段,为每一个物品生成语义ID,这个过程没有任何协同信号。
第二阶段,为每一个code学习一个嵌入向量,这个嵌入向量会在transformer阶段进行更新,会融入协同信息。
通过LLM训练注入协同信号的缺点:有相似语义的两个项目总是共享相似的标记序列和嵌入,难以与协同信号对齐。通过训练将协同信号注入这两个项目的标识符嵌入会导致冲突。
2.METHOD
2.1 LETTER
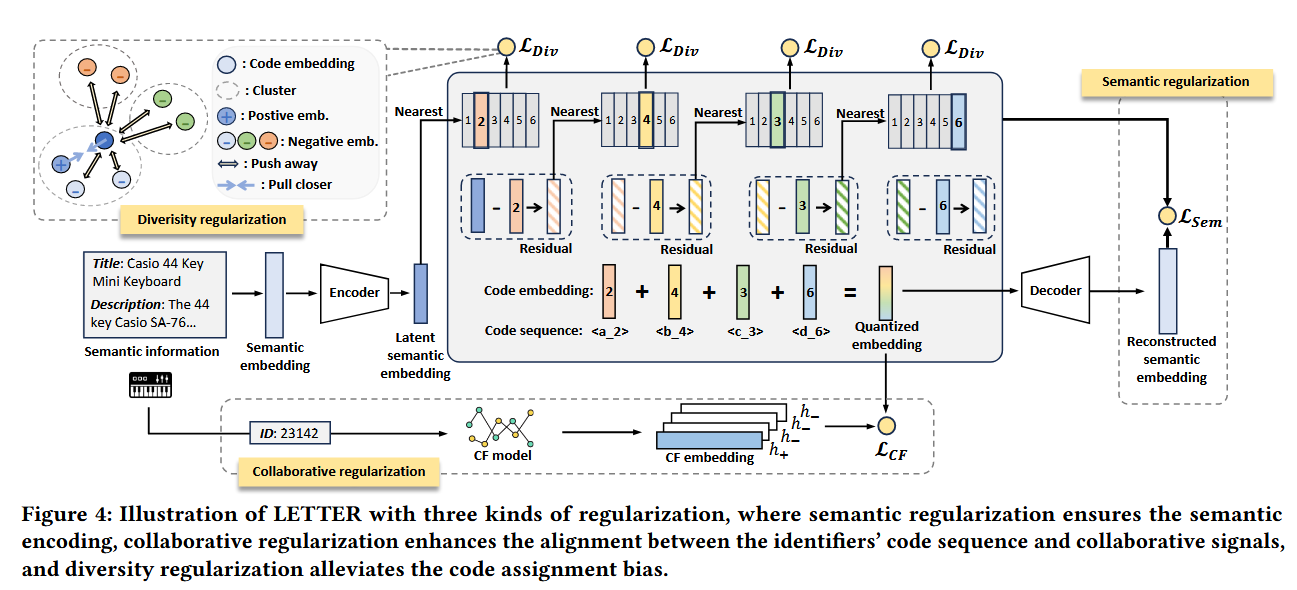
2.1.1 语义正则化模块
这部分内容与TIGER里的处理基本一致。
-
语义嵌入提取
给定具有内容信息(如标题和描述)的项目,我们首先通过预训练的语义提取器(如LLaMA-7B[41])提取语义嵌入,然后通过编码器Encoder将语义嵌入压缩为潜在语义嵌入。 -
语义嵌入量化
潜在语义嵌入随后通过级码本量化为码序列,其中为标识符长度。具体而言,对于每个码级别,我们有一个码本,其中是可学习码嵌入,表示码本大小。随后,残差量化可表述为:其中是从第l级码本分配的码索引,是上一级的语义残差,我们设。直观上,在每级码本中,LETTER找到与语义残差最相似的码嵌入,并为项目分配相应的码索引。经过递归量化后,我们最终获得量化标识符和量化嵌入。量化嵌入随后被解码为重构的语义嵌入。语义正则化的损失函数表述为:
其中是停止梯度操作[42],是平衡码嵌入优化与编码器强度的系数。
-
损失函数作用:
减少所有级别的残差误差,并联合训练编码器和码嵌入。
重构损失旨在保持潜在空间中的基本语义信息,使得语义嵌入可从量化嵌入重构。通过语义正则化,码序列编码层次化语义,促进从粗到细粒度的生成和冷启动泛化。
2.1.2 协同正则化
-
目的:引入协同信息
-
做法:通过
对比学习,对齐量化嵌入和CF嵌入(利用训练好的CF推荐模型比如SASREC来得到item的CF嵌入)。公式如下:其中指CF嵌入,表示内积,是批量大小。
-
公式解读/如何引入协同信息:
对于每个物品 ,它的正样本是同一个物品的 CF 嵌入 ,负样本是同一批次中其他物品的 CF 嵌入 ()。
分子鼓励 与 的内积变大,即拉近它们之间的距离。
分母鼓励 与所有其他 的内积变小,即推开它们。通过最小化这个损失,模型会调整 (量化嵌入)使得它尽可能接近 ,同时远离其他 。由于 已经富含协同信息, 在被迫对齐的过程中,自然会“吸收”这些协同信号: 的向量空间结构会逐渐与 CF 嵌入空间的结构对齐。
训练中:梯度从损失 出发,会反向传播到 ,然后进一步传播到构成 的码本向量上。然后codebook的
code embedding的结果会得到更新,从而使得最后得到的量化嵌入能更好拟合。
对比损失函数相当于一个桥梁,将 CF 嵌入空间中蕴含的协同信号传递给了量化嵌入,并通过梯度传播进一步影响到码本和码分配。 -
最终反向传播改变的是
code embedding。
2.1.3 多样性正则化
-
目的:解决码生成偏差问题,让
code embedding的分布更加均匀。 -
做法:首先对所有codebook,进行聚类操作,分为K组。之后采用损失函数:
其中是项目在第l层的最近码嵌入,表示从码的同一聚类中随机选择样本的码嵌入,表示除外码本中的所有码嵌入。(分母里面的应该是除了的所有code embedding,里面也有和属于同一类的code embedding,并不影响效果,分母里也有同一cluster的码嵌入,可能有更多的考量)
-
直观理解公式:鼓励分子变大,将同一聚类的code embedding拉近;鼓励分母变大,不同聚类的code embedding彼此推远。鼓励code embedding的多样性,来address码分配有偏差的问题。
2.2 实例化
生成推荐结果阶段。
- 传统工作的损失:
通过生成损失优化LLMs在上实现负对数似然最小化。
也就是
但是这样的损失会忽略对于所有item的排序优化,会降低推荐能力。
-
排序引导生成损失:rank-guided generation loss
指的第个标记,表示之前的标记序列,表示生成模型的可学习参数。引入温度参数,可以增强对于
苦难负样本的惩罚,进而增强排序能力。 -
排序引导损失的相关命题:(在论文附录有相关证明)
- 最小化等价于为用户优化困难负项目,其中较小的t强化对困难负样本的惩罚
- 的最小化与单向部分AUC[36]的优化相关,后者与Recall和NDCG等排序指标强相关,最终导致top-k 排序能力的提升。
-
推理阶段:
成推荐模型自回归生成码序列,表述为。
通过Tire采用约束生成,来保证生成有效标识符。
3.总结
- 在tiger生成语义ID的第一阶段,添加
协同正则化和多样性正则化,引入协同信息/应对码分配不均衡问题。 - 在生成推荐结果的第二阶段,使用改进过的,引入温度参数的,负对数似然来优化性能。