
生成式推荐Tiger
tiger作为生成式推荐里极具代表性的文章,本文主要总结TIGER的流程。
总结整个tiger实际流程
总体来看分为两个部分。(分为两个阶段每一个阶段独立训练,第一个阶段完成之后再开始第二个阶段)
- 第一个阶段.RQVAE
有三部分:
1.DNN encoder把经过LLM得到的item embedding转换为潜在的表示。
2.残差量化器输出Item的量化表示。
3.DNN decoder把量化表示返回为语义embedding
训练是为了让整个RQVAE学习到的语义ID更加符合实际情况。
每一个物品与最后对应的语义ID记录下来,用户第二阶段的推荐。- 第二阶段. 序列到序列模型。
输入:
用户历史交互序列,的序列。每一个item都转换为对应的语义ID。转换为序列。
输出:
预测的语义ID,即。
这部分的说明:我们使用开源的T5X框架[28]来实现我们的基于Transformer的编码器-解码器架构。总结:
第一阶段,调用LLM得到item的embedding,然后进行encoder得到latent representation,之后经过量化器得到语义ID,最后经过decoder再解码为最开始的embedding。
这个架构,进行训练。然后每一个item都得到对应的语义ID,这是第二阶段用到的部分。第二阶段:
序列到序列模型,用户历史交互序列,的序列。每一个item都转换为对应的语义ID。转换为序列。输出:预测的语义ID,即。使用transformer架构做这一部分的事情。
1.介绍
- 现代Recommend system采用检索和排名的策略,在检索阶段选择可能的candidate,然后根据rank model进行排名。
最后的排序阶段仅仅对检索之后的结果有作用,所以前面的检索效果很重要。
近年来,dual encoders architectures 双编码器架构也得到了扩展。
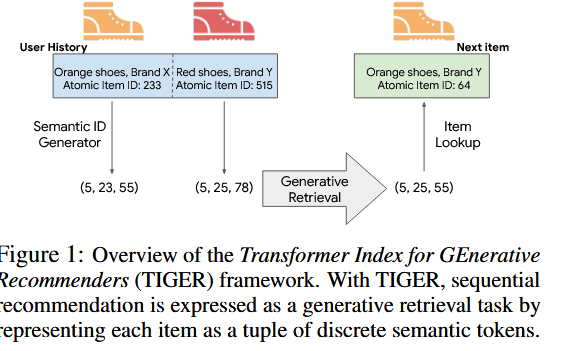
-
我们提出tiger方法。
使用端到端生成模型直接预测候选ID,而不是传统的查询候选匹配方法。TIGER的独特特征:称为语义ID,是由
每一个item的文字信息得到的一系列token。
方法上就是用一个pre-trained的encoder来讲文字信息进行embedding。
然后,在项目的嵌入上,应用量化方案,形成有序的标记/码字,称之为semantic ID.(之后用作训练transformer模型) -
将项目表示为一系列语义标记有许多优点。在语义上有意义的数据上训练Transformer内存允许在相似项目之间共享知识。这使我们可以不再使用以前在推荐模型中用作项目特征的原子和随机项目ID。使用项目的语义标记表示,模型不易受到推荐系统中固有的反馈循环的影响,从而允许模型泛化到新添加到语料库中的项目。此外,使用一系列标记进行项目表示有助于缓解与项目语料库规模相关的挑战;可以使用标记表示的项目数量是序列中每个标记的基数的乘积。通常,项目语料库的大小可以达到数十亿,为每个项目学习一个唯一的嵌入可能会占用大量内存。虽然可以采用基于随机哈希的技术来减少项目表示空间,但在这项工作中,我们展示了使用语义上有意义的标记进行项目表示是一个有吸引力的替代方案。
-
主要贡献:
1.sota. state of the art
2.新颖的,基于检索的生成式推荐框架,给每一个item分配语义ID,训练一个检索模型来预测用户之后交互物品的语义ID。
3.能推荐新的/不常见的项目,改善冷启动。可以调节参数实现多样化推荐。
3.方法
- 总结:
阶段1:生成语义ID。进行RQVAE的训练过程。
阶段2:使用语义ID来训练生成式推荐系统
3.1语义ID的生成
-
假设:
每一个Item都有相关的内容特征,比如(标题/描述/图像)。
另外一个假设是可以使用pre-trained的文本编码器比如bert将物品的文本特征转换为语义嵌入。
也就是:可以使用与训练好的content encoder将content feature转换为语义embedding。
之后,对语义embedding向量进行量化,转换为语义ID。(每一个物品都有对应的语义ID) -
讲述生成语义ID的量化方案:
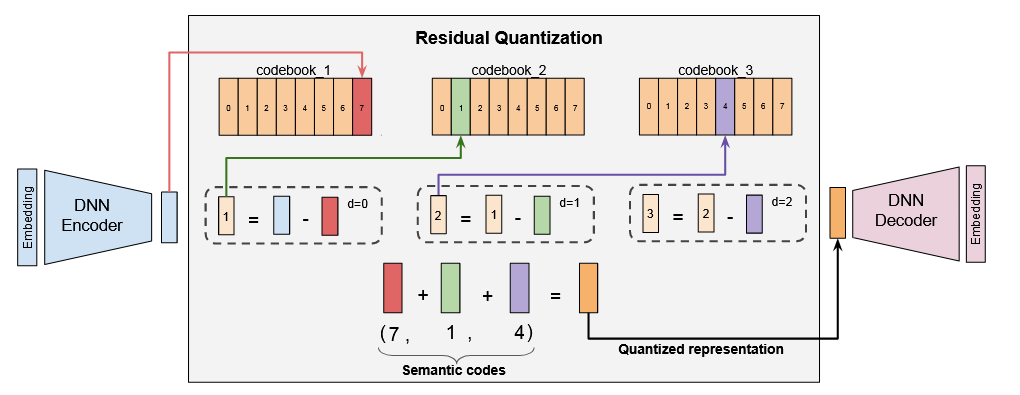
图3:RQ-VAE:图中,DNN编码器输出的向量(用蓝色条表示)被输入到量化器中,该量化器以迭代方式工作。首先,在第一级码本中找到与最近的向量。设此最近向量为(用红色条表示)。然后计算残差为。这被输入到量化器的第二级,并重复该过程:在第二级中找到与最近的向量,设为(用绿色条表示),然后计算第二级残差为。然后,对重复该过程。语义代码计算为和在各自码本中的索引。在图中示例中,这导致代码为(7, 1, 4)。 -
过程:
RQ-VAE首先通过编码器对输入进行编码,以学习潜在表示。在第零级,初始残差简单定义为。在每个级别,我们有一个码本,其中是码本大小。然后,通过将映射到该级别码本中最近的嵌入来对其进行量化。最近嵌入在时的索引,即,表示第零个码字。对于下一级,残差定义为。然后,类似于第零级,通过在第一级码本中找到与最近的嵌入来计算第一级的代码。这个过程递归地重复次,以获得表示语义ID的个码字的元组。这种递归方法从粗到细地逼近输入。注意,我们选择为每个级别使用一个大小为的单独码本,而不是使用一个大小为的单一码本。这是因为随着级别的增加,残差的范数趋于减小,因此允许不同级别具有不同的粒度。一旦我们有了语义ID,就计算出的量化表示为。然后将传递给解码器,解码器尝试使用重建输入。RQ-VAE损失定义为,其中,。这里是解码器的输出,是停止梯度操作[35]。这个损失联合训练编码器、解码器和码本。
-
损失函数与训练部分:
总损失:
其中
-
重建项(解码器尝试从 恢复 ):
这里 是解码器对 的输出。
-
RQ-VAE 的码本与承诺损失:
解释每项含义:
-
表示 **stop-gradient(停止梯度)** 操作:把括号内的张量视为常量,不对它求梯度。这是一种让不同模块“分别”更新的技巧(不像有些方法需要复杂的 EM 或交替优化)。
- 例如 在计算第一项时被当作常数,这一项的梯度只会传给码本向量 ,因此这项把码本向量拉近当前残差(用于更新码本)。
- 第二项 的梯度 只会传给编码器(影响 ,即影响 的输出),这样鼓励编码器的输出靠近被选择的码本向量(commitment loss,防止编码器在“码本附近来回抖动”)。
- 是权重,控制 **编码器对码本的“承诺”力度**(类似 VQ-VAE 中的 commitment loss)。较大 会强制 更接近所选码字,从而减少量化误差,但如果太大可能影响重构能力,需要调参。
-
表示 **stop-gradient(停止梯度)** 操作:把括号内的张量视为常量,不对它求梯度。这是一种让不同模块“分别”更新的技巧(不像有些方法需要复杂的 EM 或交替优化)。
-
3.2 使用语义ID进行生成式检索
我们通过按时间顺序排序用户交互的物品来构建每个用户的物品序列。然后,给定形式为的序列,推荐系统的任务是预测下一个物品。我们提出了一种生成式方法,直接预测下一个物品的语义ID。形式上,设是的长度语义ID。然后,我们将物品序列转换为序列。然后训练序列到序列模型以预测的语义ID,即。鉴于我们框架的生成性质,可能会出现解码器生成的语义ID与推荐语料库中的物品不匹配的情况。然而,正如我们在附录中所示(图6),这种事件发生的概率很低。我们在附录E中进一步讨论了如何处理此类事件。
3.3 最后生成式推荐环节流程举例描述
举例描述最后生成推荐的过程
假定已经有物品:
| 商品名称 | 语义 ID (由 RQ-VAE 预先学习得到) | 含义类比 |
|---|---|---|
| A: 补水洗面奶 | (12, 45, 08, 99) |
(美容, 洁面, 补水, 品牌 X) |
| B: 控油洗面奶 | (12, 45, 10, 88) |
(美容, 洁面, 控油, 品牌 Y) |
| C: 保湿精华液 | (12, 60, 22, 07) |
(美容, 护肤, 保湿, 品牌 Z) |
| D: 某款新面霜 | (12, 60, 33, 15) |
(美容, 护肤, 面霜, 品牌 K) |
假设有一个用户,他最近刚买了商品 A 和商品 B。在 TIGER 模型(通常是 T5)看来,它收到的不是两个商品,而是一串被“拍扁”的整数流:输入给 T5 Encoder 的内容:12, 45, 08, 99, 12, 45, 10, 88
现在,T5 Decoder 开始干活了。它像 GPT 生成单词一样,一个一个数字地蹦出下一个商品的 ID:
- 预测第 1 个 Token:模型根据历史,算出这一步概率最大的是
12(代表美容类)。 - 预测第 2 个 Token:模型把
12放回输入,预测下一个数字。由于用户刚买了两个洁面,模型可能觉得他该买护肤品了,于是吐出60。 - 预测第 3 个 Token:模型接着吐出
33(代表面霜)。 - 预测第 4 个 Token:模型最后吐出
15(代表品牌 K)。
最后,系统发现生成的序列是 (12, 60, 33, 15),查表得知这就是商品 D(面霜)。
最终推荐给用户的就是:面霜 D。
3.4量化的作用
引入量化的主要原因和作用:
兼容大模型:Transformer(如 T5, GPT)本质上是处理“单词”的。它不擅长直接处理无限维度的连续浮点数。量化把物品变成了“数字单词”,让大模型可以用预测文本的方式来预测物品。
量化描述:
每一个物品之前用embedding向量表示,纬度高,浮点数。量化将每一个物品用长度短,离散ID的组合来重新描述一个物品。
4.实验细节
-
实验流程:
首先我们使用Sentence-T5模型来获得每一个item的embedding。(用文字将所有相关信息给LLM,然后得到768维度的embedding结果)。
之后把embedding经过encder得到潜在表示。(就是转换为新的表示形式)
之后经过残差量化器,得到semantic id。
之后再经过decoder。DNN encoder:三个中间层大小为512 256 128.(Relu激活函数),最终转为
latent representation是32维度。
残差量化器:选三个level,每一个level里面,码本里面有256个元素,每一个元素有32的维度。训练epoch为20k.
因为选择的残差量化器是3层,所以会为每一个item生成3-tuple Semantic ID。实际细节中为了避免重复,又添加了第四个层次的标识符。